
A Transformer-Enhanced Iterative Unrolling Network for Sparse-View CT Image Reconstruction
基于Transformer增强型迭代展开网络的CT图像稀疏重建
-
Abstract:
Radiation dose reduction in Computed Tomography (CT) can be achieved by decreasing the number of projections. However, reconstructing CT images via filtered back projection algorithm from sparse-view projections often contains severe streak artifacts, affecting clinical diagnosis. To address this issue, this paper proposes TransitNet, an iterative unrolling deep neural network that combines model-driven data consistency, a physical a prior constraint, with deep learning’s feature extraction capabilities. TransitNet employs a novel iterative architecture, implementing flexible physical constraints through learnable data consistency operations, utilizing Transformer’s self-attention mechanism to model long-range dependencies in image features, and introducing linear attention mechanisms to reduce self-attention’s computational complexity from quadratic to linear. Extensive experiments demonstrate that this method exhibits significant advantages in both reconstruction quality and computational efficiency, effectively suppressing streak artifacts while preserving structures and details of images.
-
Keywords:
- Sparse-View CT /
- iterative unrolling /
- Transformer /
- linear attention /
- data consistency
摘要:通过减少投影数量可降低计算机断层扫描(CT)的辐射剂量。然而,使用滤波反投影算法从稀疏投影数据重建CT图像时会产生严重条状伪影,影响临床诊断。针对此问题,本文提出了一种基于迭代展开的深度神经网络TransitNet,将模型驱动的数据一致性与深度学习特征提取能力相结合。该网络采用新型迭代架构,通过可学习的数据一致性操作实现更灵活的物理约束,利用Transformer的自注意力机制建立图像特征的长程依赖关系,并引入线性注意力机制将自注意力的计算复杂度从平方级降低到线性级。大量实验表明,该方法在重建质量和计算效率方面均展现出显著优势,能有效抑制条状伪影,同时保持图像结构和细节。
-
关键词:
- 稀疏角度CT /
- 迭代展开 /
- Transformer /
- 线性注意力 /
- 数据一致性
-
CT serves as one of the most essential imaging tools in modern medical diagnosis, playing an irreplaceable role in clinical practice. However, X-ray radiation during CT imaging poses carcinogenic risks. To reduce radiation exposure to patients, sparse-view CT imaging technique has emerged as a solution, which reduces total radiation dose by decreasing the number of projections. While this approach effectively lowers the radiation dose, it poses challenges for image reconstruction due to incomplete projection data. Traditional analytical reconstruction methods are represented by the filtered back projection (FBP) algorithm. Although FBP features fast computation and easy implementation, making it the mainstream algorithm in commercial CT systems, its performance heavily depends on the completeness of projection data. Under sparse-view sampling conditions, FBP-reconstructed images often exhibit prominent streak artifacts, severely compromising diagnostic quality.
Research in sparse-view CT image reconstruction has evolved through three main approaches: iterative reconstruction, deep learning methods, and their integration. As a fundamental approach, iterative reconstruction methods effectively handle incomplete projection data by establishing an optimization framework between image and projection domains. At its core, this method combines data consistency constraints with regularization terms such as total variation (TV), where the data consistency ensures fidelity to measured projections while regularization helps suppress noise and artifacts, ultimately enabling high-quality reconstruction from sparse-view data. In 2006, Sidky, Pan, and colleagues proposed a sparse-view reconstruction method using total variation algorithms for divergent-beam CT imaging[1]. They further developed this in 2008 with the Adaptive-Steepest-Descent-Projection-Onto-Convex-Sets (ASD-POCS) algorithm[2], achieving quality reconstruction with only 20-view projections even with Gaussian noise. Several important variants of TV have been proposed: Do et al. introduced higher-order TV (HOTV) to reduce staircase artifacts[3]. Tian et al. proposed edge-preserving TV (EPTV) for low-contrast CT imaging[4]. Liu et al. developed adaptive-weighted TV (AwTV) to address edge over-smoothness[5]. Xu et al. proposed relative total variation (RTV) for structure extraction under texture[6]. NING et al. developed an lp norm compressive sensing approach[7]. Sidky et al. proposed total p variation (TpV) solved via Chambolle-Pock[8]. Rigie et al. introduced total nuclear variation (TnV) for better boundary preservation[9]. More recently, Zhang et al. proposed directional total variation (DTV) to preserve structural features[10]. Qiao developed a simplified ASD-POCS algorithm[11] and introduced balanced total variation (bTV) for fast convergence in EPRI[12] and directional TV method for sparse-view EPRI[13]. In 2025, Jiang et al. proposed a non-local total generalized variation (NLTGV) regularization method for sparse-view CT reconstruction, combining non-local self-similarity with variational information to enhance image quality[14]. However, iterative reconstruction methods face two major limitations: high computational cost resulting in long reconstruction times, and the difficulty in selecting optimal parameters, which has hindered their widespread clinical adoption.
Deep learning has introduced novel approaches to sparse-view CT reconstruction. As Wang highlighted in review, the intersection of X-ray imaging and deep learning presents tremendous synergistic effects and countless opportunities in this rapidly evolving field[15]. U-Net-based architectures have demonstrated particular effectiveness in artifact removal. In 2015, Ronneberger et al. proposed the U-Net with an encoder-decoder structure that was adapted from image segmentation to reconstruction[16]. In 2016, Han et al. developed a U-Net -based deep residual learning method for streak artifact removal[17]. In 2017, Jin et al. introduced FBPConvNet combining residual U-Net with FBP[18], achieving superior results over TV methods. Chen et al. proposed RED-CNN integrating residual learning through deconvolution and shortcut connections[19]. In 2018, Steven Guan introduced FD-U-Net with dense connections to reduce parameters while maintaining performance[20]. In 2020, Zheng et al. proposed a dual-domain deep learning method[21]. In 2022, Kandarpa et al. proposed a CED network using low-resolution scout images[22]. In 2023, Yu et al. proposed an unsupervised dual-domain method combining Noise2 Self and iterative enhancement[23]. Zhu et al. proposed an energy-based deep model for low-dose CT reconstruction by learning prior knowledge from normal-dose CT images[24]. In 2024, Han et al. proposed a theoretically justified dual-domain deep learning framework[25]. The Transformer architecture has opened new possibilities in computer vision through self-attention mechanisms, which enable global context modeling and capture long-range dependencies that are crucial for preserving structural details in images. In 2017, Vaswani et al. first proposed the Transformer model based on attention mechanisms[26], while Dosovitskiy et al. later adapted it for vision tasks through the Vision Transformer (ViT) model in 2020[27]. The successful application of Transformers has also benefited CT image reconstruction. In 2022, Qiao et al. proposed a CNN transformer coupling network (CTC) that combines the local feature extraction capabilities of CNN with the global information capture abilities of transformer for low-dose CT image denoising[28]. in 2023, Liu et al. proposed the D-U-Transformer network combining dense connections and Transformers[29], while Yan et al. introduced CGP-Uformer with innovative channel graph perception blocks for low-dose CT denoising[30]. Fan et al. proposed a Transformer Enhanced U-Net (TE-unet) that combines CNN with multiple attention mechanisms to effectively suppress stripe artifacts[31]. Li et al. proposed MDST, a multi-domain transformer network with improved detail preservation[32]. To address computational complexity issues, researchers have proposed various improvements: McKerahan et al. introduced linear attention mechanisms[33], Wang et al. developed Linformer with dimensionality reduction[34], Choromanski et al. proposed the Performer model using random feature mapping[35], and Shen et al. introduced Efficient Attention[36]. In 2020, Katharopoulos et al. reformulated self-attention using kernel features[37]. However, these pure deep learning approaches still face challenges. Their "black box" nature makes it difficult to interpret the reconstruction process, while their limited generalization capability can lead to degraded performance when encountering data distributions different from the training set. Moreover, these approaches lack physical consistency guarantees in their reconstructions.
Recent years have witnessed progress in combining iterative reconstruction with deep learning approaches. In 2018, Chen et al. proposed the LEARN network[38], which introduced “expert domain” generalized regularization terms into sparse-view iterative reconstruction models using CNN modules for parameter learning and updating. This pioneered adaptive adjustment of data consistency constraints. Moreover, Zhang et al. also extended the LEARN model to a dual-domain version, called LEARN++[39]. In the same year, Yu et al. developed the Deep Cascaded CNN (DC-CNN)[40], achieving gradual optimization of data consistency through cascaded modules while maintaining reconstruction quality. In 2019, Aggarwal et al. introduced MoDL with learnable data consistency layers that automatically adjust constraint strength[41], while Wang et al. proposed ADMMBDR incorporating U-Net into ADMM iterations for limited-angle CT[42]. Liao et al. presented ADN for more precise consistency constraints through explicit artifact modeling[43]. In 2020, Putzky and Welling developed RIM combining data consistency learning with recurrent networks[44]. In 2021, Xiang et al. introduced FISTA-net combining the FISTA algorithm with CNN for accelerated convergence[45], while Wu et al. integrated residual U-Net and GAN with compressed sensing for dual-domain processing optimization[46]. In 2022, Genzel et al. proposed an iterative neural network ItNet[47], Su et al. proposed a generalized unrolling scheme that learns iteration parameters, regularizer and data-fidelity terms[48]. Jia et al. proposed a superiorization-inspired unrolled SART algorithm with U-Net generated perturbations[49]. In 2024, Sun et al. proposed an efficient dual-domain deep unrolling network by alternating optimization between dense-view sinograms and images[50]. While these integrated approaches have shown promising results, most existing methods rely heavily on convolutional neural networks (CNNs) for feature extraction. Although CNNs are computationally efficient and effective at capturing local patterns, they inherently lack the ability to model long-range dependencies in image features due to their limited receptive fields. This limitation can affect the network’s capacity to preserve global structural information and handle complex artifacts that span across large image regions. The Transformer architecture, with its self-attention mechanism, offers a solution by enabling global context modeling. However, the direct application of Transformers in medical image reconstruction faces computational challenges - the standard self-attention mechanism has quadratic complexity with respect to the spatial dimensions of feature maps, making it prohibitively expensive for high-resolution medical images. To address this computational bottleneck while still leveraging the advantages of Transformers, we propose incorporating linear attention mechanisms that reduce the computational complexity from quadratic to linear.
To efficiently achieve higher reconstruction accuracy, this paper proposes TransitNet, a deep neural network based on iterative unrolling, which fully leverage the advantages of both data-driven and model-driven approaches. This method builds upon an iterative reconstruction framework, incorporating Transformers in each iteration to enhance image feature extraction capabilities while ensuring physical reliability of reconstruction results through learnable data consistency operations. Specifically, the main contributions of this paper include:
1. We Design a novel iterative neural network architecture that organically integrates model-driven data consistency, a physical a prior constraint, with deep learning’s feature extraction capabilities.
2. We introduce Transformer mechanisms with linear attention to enhance feature extraction and model long-range dependencies while reducing computational complexity from quadratic to linear.
3. We propose learnable data consistency operations that achieve more flexible physical constraints through adaptive adjustment of global and local parameters.
4. We conducted extensive experiments to validate the superior performance of our proposed method compared to existing approaches in sparse-view reconstruction tasks.
1. Methods
1.1 Iterative Framework
Iterative reconstruction progressively improves image quality through multiple rounds of optimization. Each iteration consists of two key steps: image enhancement and data consistency correction. The image enhancement step is responsible for improving the quality of reconstructed images. While traditional methods primarily rely on mathematical models such as total variation regularization, the advancement of deep learning has enabled the use of neural networks as image enhancers. The powerful feature extraction capabilities of neural networks allow them to intelligently distinguish between noise and useful information. However, in medical CT image processing, special attention must be paid to preserving diagnostically relevant details while avoiding over-processing. In data consistency correction, the current reconstructed image is first forward-projected to obtain simulated projection data, which is then compared with actual measured data to determine discrepancies. These discrepancies are transformed back to the image domain through back-projection, creating a difference image used to update the reconstruction results. Weight parameters are introduced during the update process to balance convergence speed and stability.
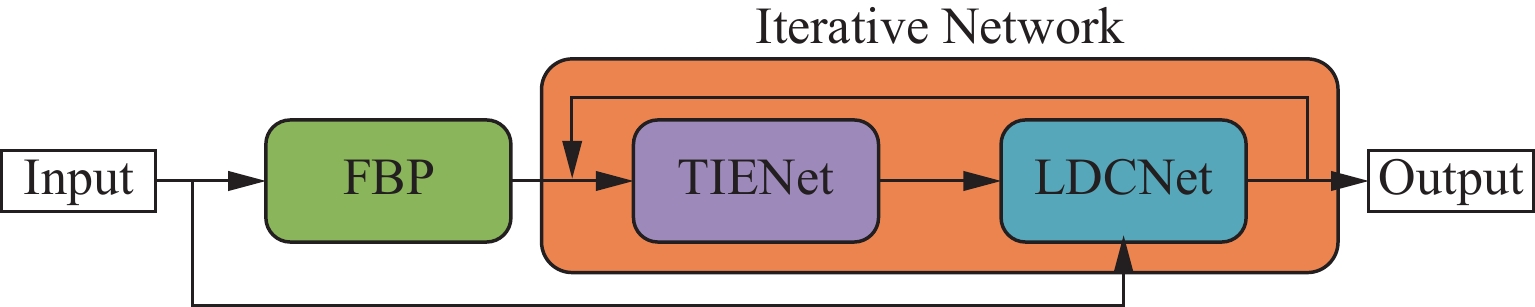
The proposed TransitNet iterative reconstruction framework is inspired by ItNet[47], which is an iterative neural network specifically designed for CT image reconstruction problems. It improves reconstruction quality by replacing computational steps in traditional iterative algorithms with learnable neural networks. In each iteration, the TransitNet network performs two main steps: first, it processes the reconstructed image using an image enhancement subnetwork (TIENet) to improve the reconstruction quality; then it performs data consistency correction (LDCNet) to adjust the reconstruction results based on discrepancies with actual measured data. Figure 1 shows the entire framework structure:
This iterative framework combining deep learning maintains the constraints of physical models, ensuring consistency between reconstruction results and measured data, while fully leveraging the powerful feature extraction capabilities of neural networks. Particularly in challenging scenarios such as low-dose imaging or incomplete data, it can achieve better results than traditional reconstruction methods. Building upon this framework, this paper will introduce improved feature extraction modules and data consistency operations to further enhance reconstruction performance.
1.2 Image Enhancement Network with Transformer Integration
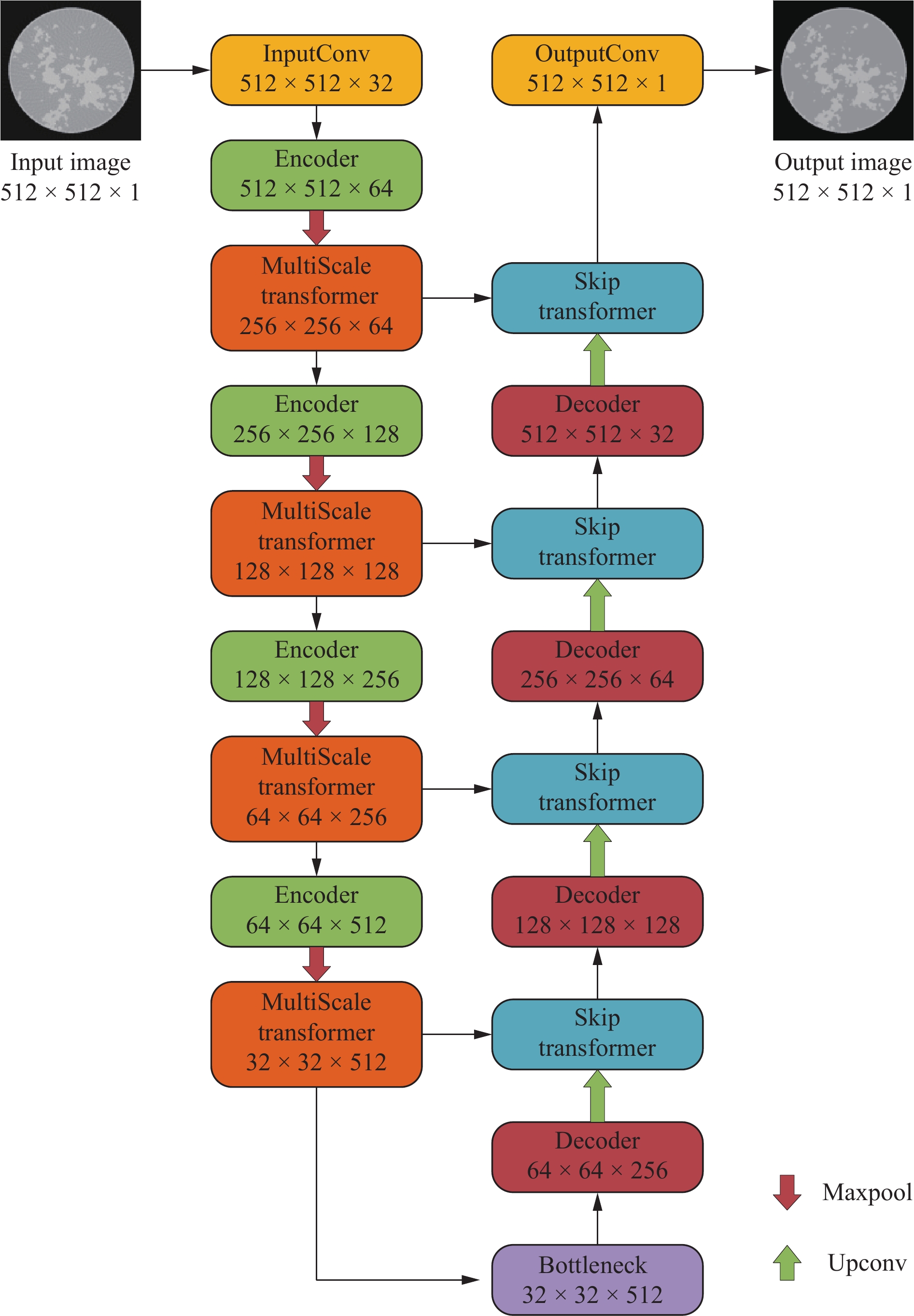
In the iterative framework, we designed a U-shaped network (U-Net) incorporating Transformer mechanisms as the image enhancement subnetwork (TIENet). While maintaining the classic encoder-decoder structure of U-Net, this network innovatively introduces multi-scale Transformer and cross-domain attention mechanisms to enhance feature extraction and information transmission capabilities. The structure of TIENet network is shown in Figure 2:
In the encoder section, the network starts with the input channels, setting the base feature channel number to 32, then progressively doubles the channel numbers across four encoding blocks. Each encoding block employs 3×3 convolution kernels with padding of 1 to maintain feature map dimensions. The group normalization uses 32 groups, which ensures effective normalization even with small batch sizes. The multi-scale Transformer module is configured with 8 attention heads, a window size of 8, and an MLP expansion ratio of 4, enabling feature relationship capture at different scales. The bottleneck layer maintains the same channel number as the final encoding block, utilizing identical convolution and normalization configurations for further feature processing. In the decoder section, four decoding blocks progressively upscale the feature map dimensions through transposed convolution, halving the channel numbers sequentially. The transposed convolution employs 3×3 kernels with a stride of 2 for upsampling. The cross-layer attention module also utilizes 8 attention heads, computing attention weights through linear projections to effectively fuse encoder and decoder features. The final output layer maps the feature maps to the specified output channels using 1×1 convolution. Throughout the network, the dropout ratio can be flexibly adjusted to control regularization intensity.
To address the quadratic computational complexity of standard Transformers in processing high-resolution medical images, this work implements an improved linear attention mechanism that operates in two key aspects: multi-scale feature extraction and cross-domain feature fusion. For multi-scale processing, the network utilizes LinearWindowAttention, which partitions input features into fixed-size windows and computes attention within each window using ELU activation and matrix multiplication instead of traditional softmax operations. For feature fusion, LinearMultiHeadCrossAttention is employed at skip connections to efficiently merge encoder and decoder features through linear projections and correlations. This dual-purpose linear attention approach reduces computational overhead while maintaining effective feature extraction and adaptive feature fusion capabilities.
The linear attention mechanism used in this paper is based on Fast Autoregressive Transformers with Linear Attention proposed by Katharopoulos et al.[37], which represents self-attention as a linear dot product of kernel feature maps and use the associativity property of matrix products to reduce the complexity from O(N2) to O(N),where N is the sequence length.
First, the computational formula for traditional attention mechanism is:
$$ Attention\left(Q,K,V\right)=softmax\left(\frac{Q{K}^{T}}{\sqrt{d}}\right)V , $$ (1) where Q (Query), K (Key), and V (Value) are learnable matrices representing different aspects of the input features, and d is the dimension of the key vectors. Q interacts with K to compute attention scores, which are then applied to V to produce the weighted output. The
$ \sqrt{d} $ term helps stabilize training by preventing the dot products from becoming too large.The core function of softmax is to normalize attention scores. Specifically, softmax maps arbitrary real numbers to the interval (0,1) with a sum of 1:
$$ softmax\left({x}_{i}\right)=\frac{{e}^{{x}_{i}}}{\displaystyle\sum _{j}{e}^{{x}_{j}}} , $$ (2) where xi represents the input value at position i, and the denominator
${\displaystyle\sum _{j}{e}^{{x}_{j}}} $ sums up the exponentials of all values in the sequence, ensuring that the outputs are normalized to sum to 1.However, this nonlinear transformation requires computing the exponential sum over the entire sequence, resulting in a computational complexity of O(N²). Based on kernel method theory, we can reformulate the attention mechanism in terms of kernel functions:
$$ Attention\left(Q,K,V\right)=\frac{\displaystyle \sum _{j}sim\left({q}_{i},{k}_{j}\right){v}_{j}}{\displaystyle \sum _{j}sim\left({q}_{i},{k}_{j}\right)} , $$ (3) where sim is the similarity function. When choosing
$ \text{sim}\left(q,k\right)=exp\left({q}^{T}k/\sqrt{d}\right) $ , it corresponds to standard softmax attention. Based on kernel function equivalence, we can use$ \varphi\left(x\right)=ELU\left(x\right)+1 $ as the feature mapping function to rewrite the attention computation as:$$ LinearAttention\left(Q,K,V\right)=\frac{{\phi }\left(Q\right)\left({\phi }{\left(K\right)}^{T}V\right)}{\displaystyle \sum _{j}{\phi }{\left(K\right)}_{j}+\varepsilon} , $$ (4) where
$ {\phi } $ denotes the feature mapping function, ε is a small constant to ensure numerical stability, and the denominator$ \displaystyle \sum _{j}{\phi }{\left(K\right)}_{j} $ is to normalize attention scores. Meanwhile, the computational mechanisms of each Transformer module will undergo corresponding modifications. The multi-scale Transformer component consists of attention computation and multi-head attention integration, calculated as follows:$$ \mathrm{M}\mathrm{S}\mathrm{A}\left(\mathrm{X}\right)=\displaystyle \sum _{\mathrm{i}=1}^{\mathrm{h}}\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{i}\mathrm{o}{\mathrm{n}}_{\mathrm{i}}\left({\mathrm{W}}_{\mathrm{Q}}^{\mathrm{i}}\mathrm{X},{\mathrm{W}}_{\mathrm{K}}^{\mathrm{i}}\mathrm{X},{\mathrm{W}}_{\mathrm{V}}^{\mathrm{i}}\mathrm{X}\right){\mathrm{W}}_{\mathrm{O}}^{\mathrm{i}} , $$ (5) where h is the number of attention heads,
$ {W}_{Q}^{i} $ ,$ {W}_{K}^{i} $ ,$ {W}_{V}^{i} $ are the linear transformation matrices for the i-th head, and$ {W}_{O}^{i} $ is the output projection matrix for the i-th head.The cross-domain attention module includes cross-attention computation and cross-layer feature fusion, calculated as follows:
$$ CLA\left({X}_{1},{X}_{2}\right)=\frac{{\phi }\left({Q}_{1}\right){{\phi }\left({K}_{2}\right)}^{T}{V}_{2}}{\left(\displaystyle \sum _{j}{\phi }\left({K}_{2j}\right)+\varepsilon\right)} , $$ (6) where
$ {X}_{1} $ and$ {X}_{2} $ represent low-level and high-level features respectively,$ {Q}_{1}={W}_{q{X}_{1}} $ is the query transformation of low-level features, and$ {K}_{2}={W}_{k{X}_{2}} $ ,$ {V}_{2}={W}_{v{X}_{2}} $ are the key-value transformations of high-level features.$$ Fusion\left({X}_{1},{X}_{2}\right)=Concat\left[{X}_{1},CLA\left({X}_{1},{X}_{2}\right)\right]{W}_{p} , $$ (7) where Concat represents the concatenation operation along the channel dimension,
$ {W}_{p} $ is the final projection matrix,$ {X}_{1} $ represents low-level features, and$ {X}_{2} $ represents high-level features.Convolutional operations excel at extracting local features, while Transformer mechanisms are adept at establishing long-range dependencies. The combination of these two enables the network to perform exceptionally well in preserving detailed structures and suppressing noise. Finally, the features are mapped to the output space through a 1×1 convolutional layer to complete the image enhancement task.
1.3 Learnable Data Consistency
Data consistency operation is a crucial step in CT image reconstruction, with its core concept being to ensure consistency between the reconstructed image and actual measured data in the projection domain. Traditional data consistency operations project the reconstructed image into the sinogram domain through Radon transform, compute the residual with measured data, and then map the residual back to the image domain through back-projection for updates. This process can be expressed as:
$$ x=x+\lambda {A}^{T}\left(y-Ax\right) , $$ (8) where x is the reconstructed image, y is the measured data,
$ A $ and$ {A}^{T} $ are the forward and backward projection operators respectively, and λ is the weight coefficient controlling the update step size.To enhance the adaptability and performance of data consistency operations, this paper proposes a learnable data consistency network structure (Learnable Data Consistency Net, LDCNet). This network first concatenates the current reconstructed image and data consistency term along the channel dimension, processing them through a feature extraction network. The feature extraction network employs a residual structure and dual attention mechanism, where the residual structure facilitates learning residual information and prevents gradient vanishing, while the channel attention and spatial attention mechanisms adaptively adjust the importance of features.
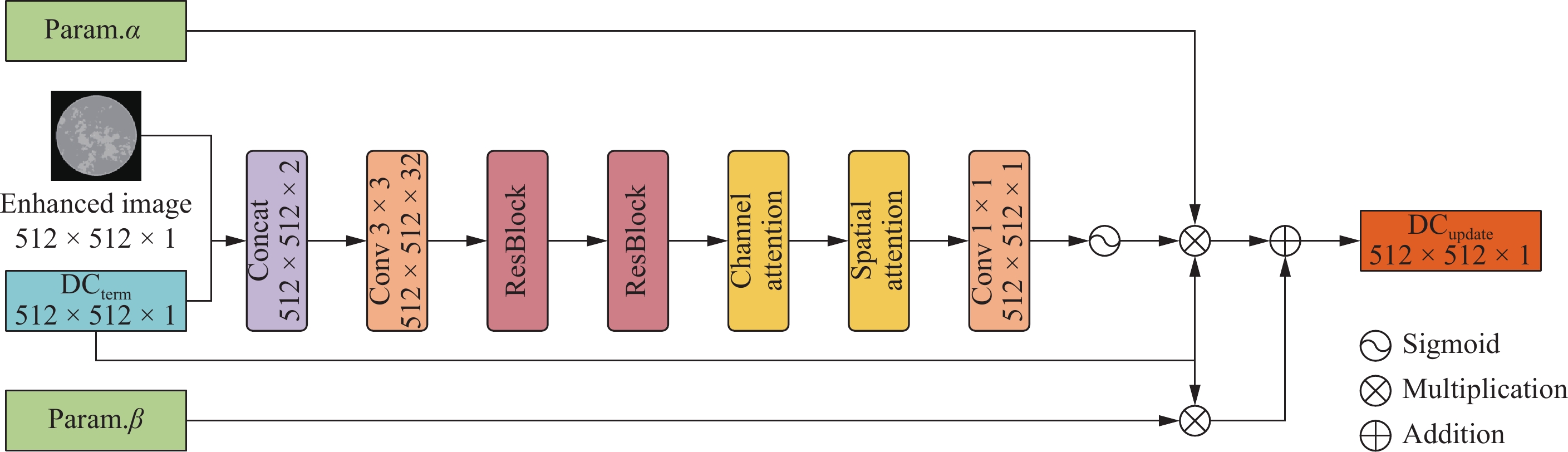
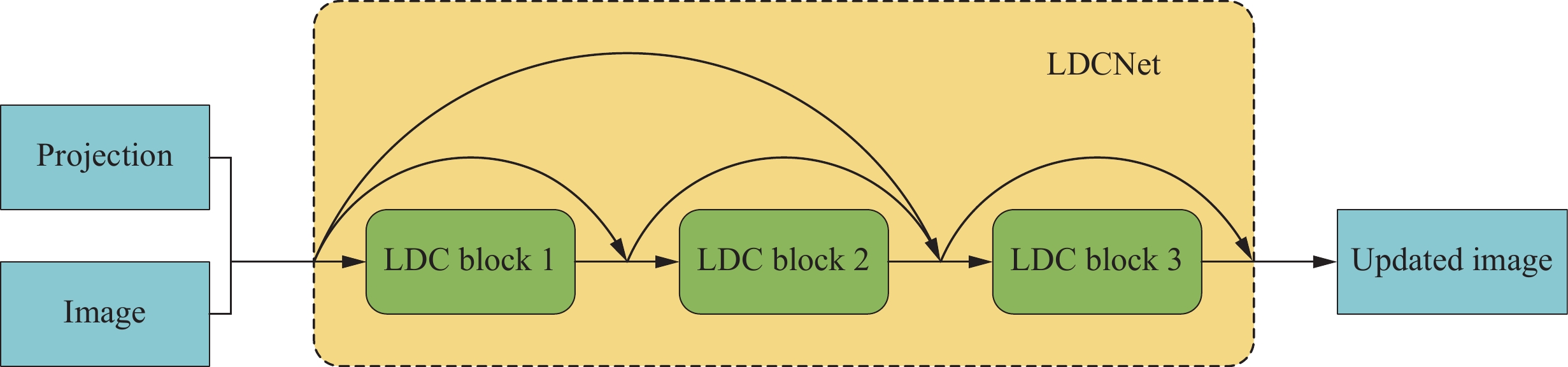
First, we introduce the LDC Block, which is the basic building unit of the data consistency processing module. When input data enters the LDC Block, the current reconstructed image and data consistency term are first concatenated along the channel dimension, allowing the network to simultaneously access both types of information. The concatenated data then passes through a feature extraction and transformation network, which begins with convolutional layers and processes features through residual blocks, channel attention, and spatial attention modules. This multi-level feature extraction and attention-enhanced design enables LDCNet to adaptively learn the weight distribution of data consistency. Figure 3 depicts the structure of LDC block.
Each LDC Block has its own weight parameter alpha and bias parameter beta, which are automatically adjusted during training to form a flexible dual-path regulation mechanism. The α parameter controls the influence of the data consistency term after processing through the feature network, while the β parameter acts directly on the original data consistency term, providing a linear bypass channel. This design enables the network to dynamically adjust its update strategy at each iteration step based on specific conditions. The computation is as follows:
$$ D{C}_{update}=\mathrm{\alpha }W\odot D{C}_{term}+\mathrm{\beta }D{C}_{term} . $$ (9) Of particular note is the weight map generated by the network, which assigns a weight value between 0 and 1 to each pixel position, achieving spatial adaptability of data consistency constraints. This enables the network to learn to identify which regions require stronger data consistency constraints and which regions can be relatively relaxed, thereby effectively suppressing noise and artifacts while preserving important structures. The weight map is computed as follows:
First, compute the feature extraction network:
$$ F\left({X}_{curr},D{C}_{term}\right)=\mathrm{\sigma }\left(Conv\left(Concat\left[{X}_{curr},D{C}_{term}\right]\right)\right) . $$ (10) Then compute the attention-enhanced weight map:
$$\begin{aligned} &W=SA\left(CA\left(Res\left(F\right)\right)\right)=\\ &SA\left(\frac{\displaystyle\sum _{c}\left(MaxPool\left({F}_{c}\right)+AvgPool\left({F}_{c}\right)\right)}{2}\right)\odot CA\left(F\right) , \end{aligned}$$ (11) where Res denotes the residual block operation, CA represents channel attention, SA represents spatial attention, and ⊙ denotes element-wise multiplication.
The learnable data consistency layer LDCNet serves as a high-level encapsulation of the entire module, containing multiple LDC Block instances that match the number of iterations. Each LDC Block corresponds to a specific iteration update, maintaining identical network architecture but with independent learnable parameters. During forward propagation, the network selects the appropriate LDC Block for processing based on the current iteration index. For example, at iteration t, the t-th LDC Block is activated to process the data. This design allows the network to adaptively adjust the strength of data consistency constraints at different iteration stages. The optimal number of iterations was determined through experimental validation, which is detailed in the discussion section. The structure of LDCNet is shown in Figure 4.
Additionally, LDCNet introduces global weight and bias parameters to regulate the intensity of data consistency constraints at a higher level. The global weight serves as a scaling factor that uniformly adjusts the intensity of data consistency updates across all iteration steps, while the global bias provides baseline adjustment for the data consistency term. These two global parameters are automatically learned through backpropagation, enabling the model to holistically adapt to different reconstruction tasks and data characteristics. The image update computation is as follows:
$$ {X}_{t+1}={X}_{t}-\left({w}_{global}D{C}_{update}+{b}_{global}D{C}_{term}\right) . $$ (12) 2. Results
2.1 Dataset
This study utilizes the dataset provided by the DL-sparse-view CT competition in the AAPM Grand Challenge (https://www.aapm.org/GrandChallenge/DL-sparse-view-CT/). The dataset consists of
4000 training images with dimensions of 512×512 pixels, generated from breast phantom simulations, with an additional 10 images for testing. The simulation model features complex random structures within circular cross-sections, designed to simulate fibroglandular tissue in the breast. Each training image is accompanied by corresponding projection data (sinograms) acquired through 360-degree fan-beam projections with 128 views. Additionally, the dataset includes reconstructed images obtained using the FBP algorithm applied to these 128-view projection data.2.2 Implementation Details
All experiments were conducted on a workstation equipped with an NVIDIA RTX
3090 GPU (24 GB memory), dual Jintide M88 JTMX08101 processors (16 cores 32 threads each at 2.1 GHz), 128 GB DDR4 RAM, running Ubuntu 22.04 LTS operating system.For the training strategy, we adopted a multi-stage training approach, first pre-training the image enhancement subnetwork TIENet, followed by training the TransitNet. During the training process, we utilized the Adam optimizer with an initial learning rate of 1 e-3 and implemented a learning rate decay strategy. Due to computational resource constraints, the batch size was set to 2 and the epochs number was set to 100. To enhance the model’s generalization capability, we employed 10-fold cross-validation for data partitioning, training the model separately on each fold. The loss function incorporated MSE, along with supervision from multiple image quality assessment metrics including RMSE, PSNR, and SSIM.
For comparative experiments, we also employed 10-fold cross-validation, with batch sizes adjusted according to available computational resources, and the same number of epochs as used in training TransitNet.
2.3 Evaluation Metrics
To comprehensively evaluate the performance of reconstruction algorithms, this study employs three complementary image quality metrics: Root Mean Square Error (RMSE), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM). The formulas for calculating RMSE, PSNR, SSIM are as follows:
$$ RMSE=\sqrt{\frac{1}{MN}\displaystyle\sum_{i=1}^{M}\displaystyle\sum _{j=1}^{N}{\left({x}_{ij}-\widehat{{x}_{ij}}\right)}^{2}} , $$ (13) where
$ {x}_{ij} $ and$ \widehat{{x}_{ij}} $ represent the pixel values at position$ (i,j) $ in the reference image and reconstructed image respectively, and M and N denote the height and width of the image.$$ PSNR=10{\mathrm{log}}_{10}\left(\frac{MA{X}_{I}^{2}}{MSE}\right)=20{\mathrm{log}}_{10}\left(\frac{MA{X}_{I}}{\sqrt{MSE}}\right) , $$ (14) where
$ MA{X}_{I} $ represents the maximum possible pixel value of the image (e.g., 255 for an 8-bit image), and MSE is the Mean Square Error.$$ SSIM=\frac{\left(2{\mathrm{\mu }}_{x}{\mathrm{\mu }}_{y}+{c}_{1}\right)\left(2{\mathrm{\sigma }}_{xy}+{c}_{2}\right)}{\left({\mathrm{\mu }}_{x}^{2}+{\mathrm{\mu }}_{y}^{2}+{c}_{1}\right)\left({\mathrm{\sigma }}_{x}^{2}+{\mathrm{\sigma }}_{y}^{2}+{c}_{2}\right)} , $$ (15) where
$ {\mathrm{\mu }}_{x} $ and$ {\mathrm{\mu }}_{y} $ are the means of images x and y respectively,$ {\mathrm{\sigma }}_{x}^{2} $ and$ {\mathrm{\sigma }}_{y}^{2} $ are the variances,$ {\mathrm{\sigma }}_{xy} $ is the covariance, and$ {c}_{1} $ and$ {c}_{2} $ are small constants to prevent division by zero.2.4 Quantitative Results
This section compares the performance of different reconstruction algorithms on the AAPM dataset. The experiment evaluates several representative algorithms, including the traditionalFBP algorithm, deep learning-based FBPConvNet and RED-CNN, Transformer-based Uformer and SwinIR, iterative optimization-based TV and RTV methods, and our proposed TransitNet. To comprehensively assess the performance of each algorithm, the analysis was conducted from two dimensions: quantitative metrics and visual quality. The quantitative evaluation employs three complementary image quality metrics - RMSE, SSIM, and PSNR, while the visual quality analysis evaluates the reconstruction effectiveness of different algorithms by comparing the detail representation of reconstructed images.
As shown in Table 1, TransitNet exhibits superior performance across all quantitative metrics. Specifically, TransitNet achieves a PSNR of
45.8486 dB, which represents a substantial improvement of19.0084 dB over the traditional FBP algorithm (26.8402 dB). In comparison with deep learning-based methods, TransitNet significantly outperforms RED-CNN (33.0535 dB), FBPConvNet (36.4081 dB), and more recent Transformer-based architectures including Uformer (38.1376 dB) and SwinIR (37.2184 dB). When compared to iterative optimization methods, TransitNet demonstrates superior performance with an RMSE of0.0051 , notably lower than both TV (0.0198 ) and RTV (0.0163 ). Furthermore, TransitNet achieves a higher PSNR (45.8486 dB vs42.2334 dB) and SSIM (0.9590 vs0.9018 ) compared to the baseline ItNet model, quantitatively validating the effectiveness of our proposed network enhancements.Table 1. Results of Various Reconstruction AlgorithmsAlgorithms RMSE PSNR SSIM FBP 0.0455 26.8402 0.6003 RED-CNN 0.0222 33.0535 0.8613 FBPConvNet 0.0151 36.4081 0.8922 SwinIR 0.0138 37.2184 0.9187 Uformer 0.0124 38.1376 0.9423 TV 0.0198 34.0534 0.9976 RTV 0.0163 35.7495 0.9983 ItNet 0.0077 42.2334 0.9018 TransitNet 0.0051 45.8486 0.9590 2.5 Visual Quality Results
From the visual quality comparison of reconstructed images, deep learning-based FBPConvNet and RED-CNN can suppress noise to some extent, but their detail preservation is less than ideal. Transformer-based Uformer and SwinIR show improvements in detail preservation, but still suffer from a certain degree of blurring. The iterative optimization-based TV and RTV methods achieve a good balance between artifacts suppression and detail preservation, though they show slightly insufficient edge sharpness. In contrast, our proposed TransitNet not only effectively suppresses artifacts but also excellently preserves image detail structures, producing reconstructed images that more closely resemble the reference images and demonstrating optimal visual reconstruction effects. Moreover, the images reconstructed by the FBP algorithm exhibited conspicuous artifacts and lacked reference value; therefore, the resultant image were not presented in the paper.
2.6 Ablation Studies
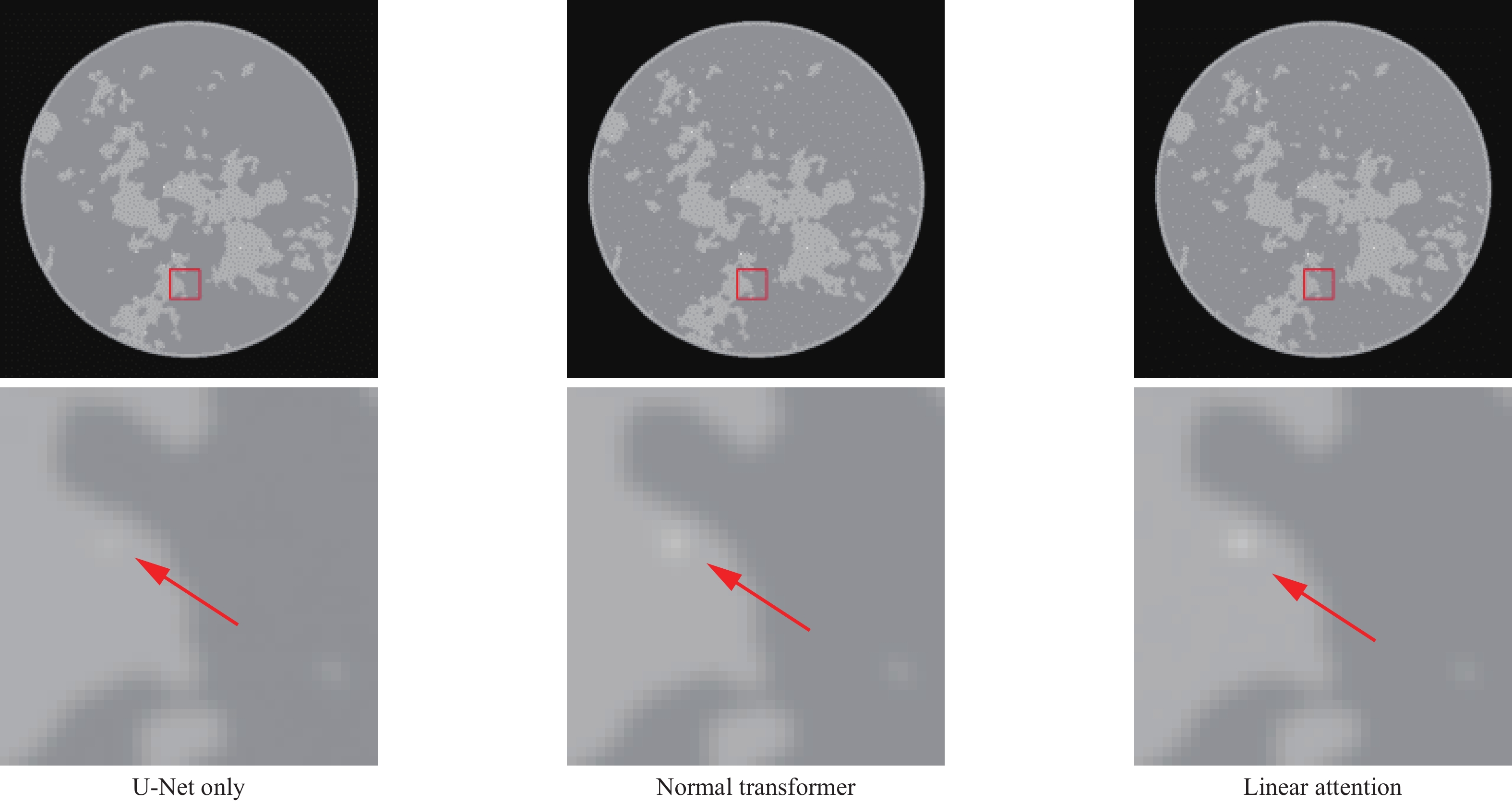
To validate the effectiveness of key modules in the proposed method, we conducted a series of ablation studies. First, we compared the performance of three different network architectures: using U-Net alone, using standard Transformer, and using linear attention mechanism, which verified the roles of the Transformer module and linear attention mechanism. Subsequently, by comparing fixed-weight and learnable-weight data consistency schemes, we validated the necessity of the learnable data consistency module.
2.6.1 Validating the Effects of Transformer Module and Linear Attention Mechanism
As shown in Table 2, incorporating the Transformer module enhances reconstruction performance, with the standard Transformer showing nearly 6 dB improvement in PSNR, 48% reduction in RMSE, and 0.1 increase in SSIM compared to using U-Net alone. However, the standard Transformer introduces substantial computational overhead, with parameter count increasing by 60% from 30 M to 48.3 M, FLOPs rising from 96.47 G to 178.94 G, memory consumption increases from 4.6 GB to 28.4 GB, training time grows from 7.2 h to 34.2 h. After implementing the linear attention mechanism, although there is a 1.8 dB decrease in PSNR compared to the standard Transformer, it still maintains a 4 dB advantage over U-Net while reducing FLOPs by 30% (from 178.94 G to 124.86 G), and parameter count by 18% (from 48.3 M to 39.6 M), memory usage by 53% (from 28.4 GB to 13.3 GB), and training time by 34% (from 34.2 h to 22.6 h). This indicates that the linear attention mechanism serves as an effective optimization strategy, maintaining most performance benefits while improving computational efficiency.
Table 2. Results of Different Image Enhance NetImage Enhance Net Training Time∕min/epoch #param. FLOPs Memory/GB RMSE PSNR SSIM U-Net Only 7.2 30 M 96.47 G 4.6 0.0079 42.2568 0.8636 Normal Transformer 34.2 48.3 M 178.94 G 28.4 0.0041 48.1445 0.9642 Transformer with Linear Attention 22.6 39.6 M 124.86 G 13.3 0.0051 45.8486 0.9590 Comparing the visual effects of reconstructed images, it is evident that using U-Net alone results in noticeable blurring and loss of details. After introducing the standard Transformer, image clarity and detail representation are improved, with sharper edges and more complete structural preservation. Although the linear attention mechanism scheme is slightly inferior to the standard Transformer in detail preservation, it still notably outperforms the pure U-Net architecture while reducing computational overhead while maintaining good reconstruction quality. These visual effects align with the trends observed in quantitative metrics, further validating the effectiveness of the Transformer module and linear attention mechanism. Overall, the linear attention scheme achieves the optimal balance between reconstruction quality and computational resource consumption, proving to be a practical improvement solution.
2.6.2 Validating the Effectiveness of Learnable Data Consistency
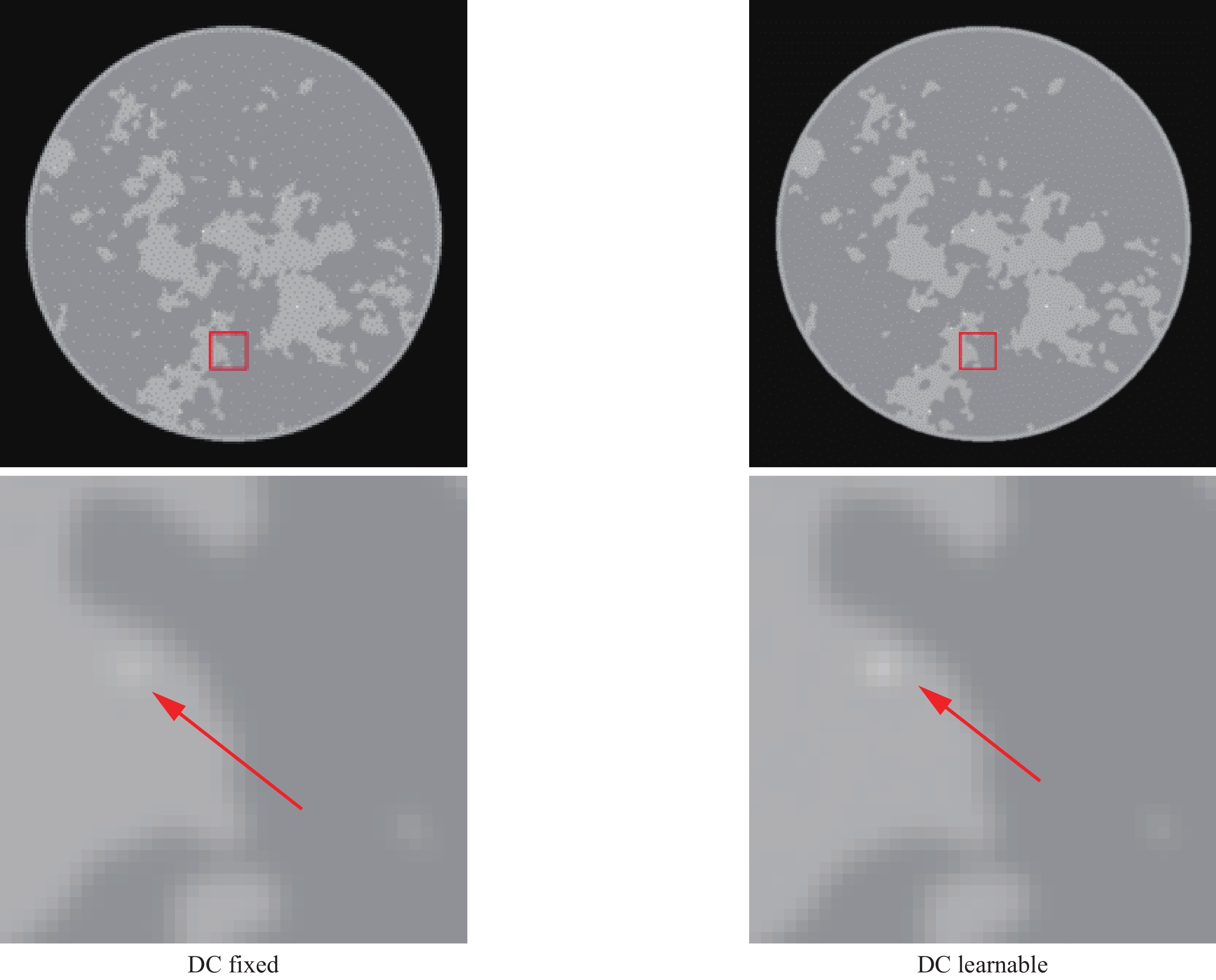
The data in Table 3 reveals that the learnable data consistency module achieves performance improvements compared to the fixed-weight approach. In terms of RMSE, the learnable scheme achieves
0.0051 , representing a 24% reduction from the fixed-weight value of 0.0067. The SSIM increases from0.9188 to0.9590 , showing an improvement of 0.04. The enhancement in PSNR is particularly notable, rising from43.8670 dB to45.8486 dB, demonstrating a substantial improvement of 2 dB.Table 3. Results of Fixed and Learnable Data ConsistencyData Consistency RMSE SSIM PSNR Fixed 0.0067 0.9188 43.8670 Learnable 0.0051 0.9590 45.8486 Comparison of reconstructed images reveals that the fixed-weight data consistency scheme produces images with noticeable blurring and artifacts. In contrast, the learnable weight approach not only better suppresses noise and artifacts but also better preserves image detail structures and edge features, resulting in clearer and more natural reconstructed images. These visual improvements align with the enhancement in quantitative metrics, further validating the effectiveness of the learnable data consistency module. The results from both aspects demonstrate that by learning learnable data consistency weights, the network can better balance the fidelity of measurement data and reconstruction image quality, thereby achieving superior reconstruction results.
3. Discussion
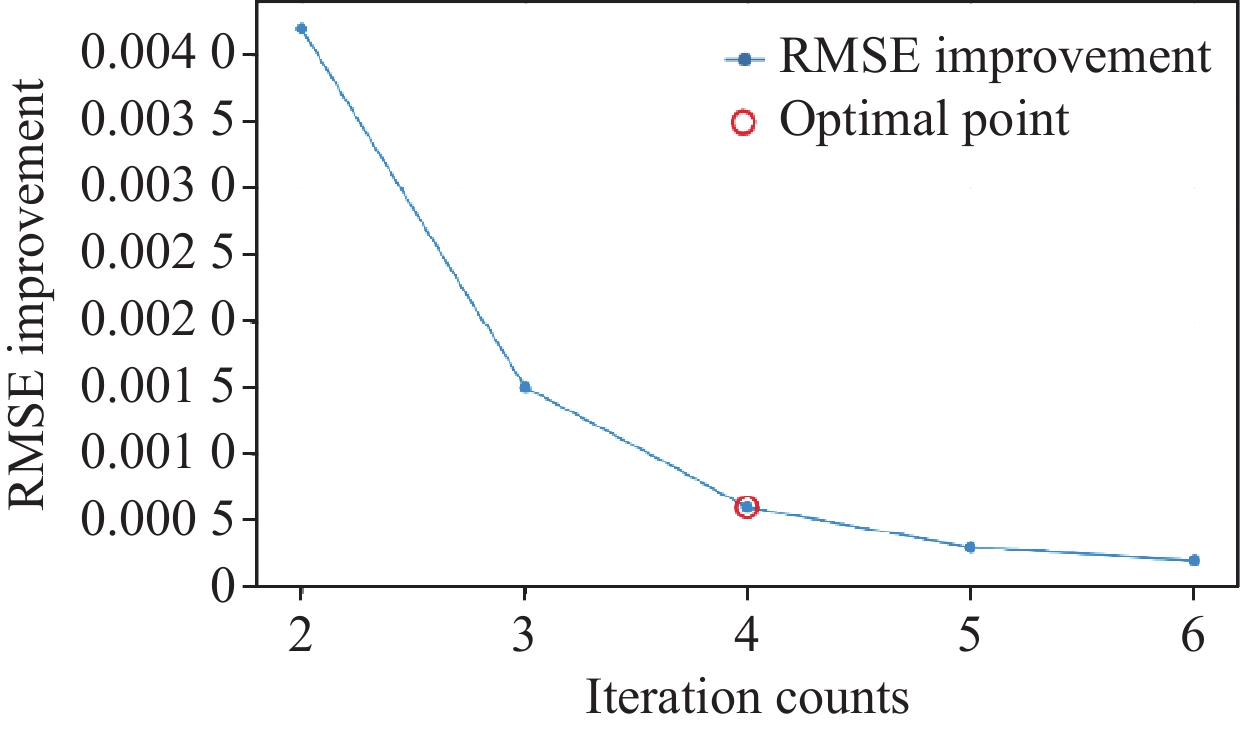
Table 4 demonstrates the variation of different evaluation metrics with respect to the iteration count. Figure 9 illustrates the improvement in reconstruction quality with each additional iteration. The analysis of iteration count’s impact on reconstruction performance reveals a consistent improvement trend in reconstruction quality as the number of iterations increases. With fewer iterations, each additional iteration brings notable performance enhancement, indicating that the network can progressively refine and optimize reconstruction results through multiple iterations. Specifically, when increasing the iteration count from 3 to 4, we observe a significant PSNR improvement of approximately 1 dB, while the improvement from 4 to 5 iterations yields only 0.5 dB gain. Moreover, the training time increases approximately linearly with the number of iterations. After reaching four iterations, the rate of performance improvement begins to plateau, suggesting that the network has essentially converged to a stable state. Although further increasing the iteration count still yields marginal performance improvements, considering the additional computational overhead and the diminishing returns in reconstruction quality, four iterations achieve an optimal balance between reconstruction quality and computational efficiency. This iterative convergence characteristic resembles traditional iterative reconstruction algorithms, demonstrating that the proposed deep learning framework inherits the advantageous properties of iterative reconstruction while accelerating convergence through learnable network modules. Furthermore, the continuous improvement in reconstruction quality indirectly validates the rationality of the network design, indicating that each iteration effectively extracts and utilizes image information.
Table 4. Results with Different Iteration CountsIteration
CountsTraining
Time∕min/epochRMSE SSIM PSNR 1 11.2 0.0115 0.8387 38.7860 2 15.2 0.0072 0.8636 42.8534 3 18.8 0.0057 0.9341 44.8825 4 22.6 0.0051 0.9590 45.8486 5 26.3 0.0048 0.9715 46.3752 6 29.8 0.0046 0.9734 46.7448 4. Conclusions
This paper presents TransitNet, an unrolling-based deep neural network for low-dose CT image reconstruction. The method organically combines physics model-driven data consistency constraints with deep learning’s feature extraction capabilities, achieving high-quality reconstruction through the introduction of Transformer mechanisms and learnable data consistency operations. Experimental results demonstrate that TransitNet achieves a good balance between reconstruction quality and computational efficiency. The incorporation of Transformer modules enhances reconstruction performance, while the linear attention mechanism effectively reduces computational overhead while maintaining most performance advantages. The learnable data consistency module enables better balance between measurement data fidelity and reconstruction image quality through adaptive weight adjustment. Experiments with iteration counts show that the network reaches a stable state after 4 iterations, demonstrating rapid convergence. Compared to existing methods, TransitNet not only effectively suppresses noise and artifacts but also well preserves image detail structures, showing excellent performance in both quantitative metrics and visual quality. These results indicate that combining deep learning with traditional reconstruction methods is a promising research direction, and the framework proposed in this paper provides an effective solution for this approach. Future work can further explore more efficient attention mechanisms and data consistency optimization strategies to further improve reconstruction performance and computational efficiency.
-
Table 1 Results of Various Reconstruction Algorithms
Algorithms RMSE PSNR SSIM FBP 0.0455 26.8402 0.6003 RED-CNN 0.0222 33.0535 0.8613 FBPConvNet 0.0151 36.4081 0.8922 SwinIR 0.0138 37.2184 0.9187 Uformer 0.0124 38.1376 0.9423 TV 0.0198 34.0534 0.9976 RTV 0.0163 35.7495 0.9983 ItNet 0.0077 42.2334 0.9018 TransitNet 0.0051 45.8486 0.9590  下载: 导出CSV
下载: 导出CSV
Table 2 Results of Different Image Enhance Net
Image Enhance Net Training Time∕min/epoch #param. FLOPs Memory/GB RMSE PSNR SSIM U-Net Only 7.2 30 M 96.47 G 4.6 0.0079 42.2568 0.8636 Normal Transformer 34.2 48.3 M 178.94 G 28.4 0.0041 48.1445 0.9642 Transformer with Linear Attention 22.6 39.6 M 124.86 G 13.3 0.0051 45.8486 0.9590
下载: 导出CSV
Table 3 Results of Fixed and Learnable Data Consistency
Data Consistency RMSE SSIM PSNR Fixed 0.0067 0.9188 43.8670 Learnable 0.0051 0.9590 45.8486
下载: 导出CSV
Table 4 Results with Different Iteration Counts
Iteration
CountsTraining
Time∕min/epochRMSE SSIM PSNR 1 11.2 0.0115 0.8387 38.7860 2 15.2 0.0072 0.8636 42.8534 3 18.8 0.0057 0.9341 44.8825 4 22.6 0.0051 0.9590 45.8486 5 26.3 0.0048 0.9715 46.3752 6 29.8 0.0046 0.9734 46.7448
下载: 导出CSV
-
[1] SIDKY E Y, KAO C M, PAN X. Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT[J/OL]. Journal of X-Ray Science and Technology: Clinical Applications of Diagnosis and Therapeutics, 2006, 14(2): 119-139. DOI: 10.3233/XST-2006-00155.
[2] SIDKY E Y, PAN X. Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization[J/OL]. Physics in Medicine and Biology, 2008, 53(17): 4777-4807. DOI: 10.1088/0031-9155/53/17/021.
[3] DO S, KARL W C, KALRA M K, et al. Clinical low dose CT image reconstruction using high-order total variation techniques[C/OL]//SPIE Medical Imaging. San Diego, California, United States, 2010: 76225D [2025-02-13]. http://proceedings.spiedigitallibrary.org/proceeding.aspx?doi= 10.1117/12.844307. DOI: 10.1117/12.844307.
[4] TIAN Z, JIA X, YUAN K, et al. Low-dose CT reconstruction via edge-preserving total variation regularization[J/OL]. Physics in Medicine and Biology, 2011, 56(18): 5949-5967. DOI: 10.1088/0031-9155/56/18/011.
[5] LIU Y, MA J, FAN Y, et al. Adaptive-weighted total variation minimization for sparse data toward low-dose x-ray computed tomography image reconstruction[J/OL]. Physics in Medicine and Biology, 2012, 57(23): 7923-7956. DOI: 10.1088/0031-9155/57/23/7923.
[6] XU L, YAN Q, XIA Y, et al. Structure extraction from texture via relative total variation[J/OL]. ACM Transactions on Graphics, 2012, 31(6): 1-10. DOI: 10.1145/2366145.2366158.
[7] Ning Fang-Li, He Bi-Jing, Wei Juan, et al. An algorithm for image reconstruction based on lp norm[J/OL]. Acta Physica Sinica, 2013, 62(17): 174212. DOI: 10.7498/aps.62.174212.
[8] SIDKY E Y, CHARTRAND R, BOONE J M, et al. Constrained TpV minimization for enhanced exploitation of gradient sparsity: Application to CT image reconstruction[J/OL]. IEEE Journal of Translational Engineering in Health and Medicine, 2014, 2: 1-18. DOI: 10.1109/JTEHM.2014.2300862.
[9] RIGIE D S, LA RIVIÈRE P J. Joint reconstruction of multi-channel, spectral CT data via constrained total nuclear variation minimization[J/OL]. Physics in Medicine and Biology, 2015, 60(5): 1741-1762. DOI: 10.1088/0031-9155/60/5/1741.
[10] ZHANG Z, CHEN B, XIA D, et al. Directional-TV algorithm for image reconstruction from limited-angular-range data[J/OL]. Medical Image Analysis, 2021, 70: 102030. DOI: 10.1016/j.media.2021.102030.
[11] QIAO Z. A simple and fast ASD-POCS algorithm for image reconstruction[J/OL]. Journal of X-Ray Science and Technology, 2021, 29(3): 491-506. DOI: 10.3233/XST-210858.
[12] QIAO Z, REDLER G, EPEL B, et al. A balanced total-variation-Chambolle-Pock algorithm for EPR imaging[J/OL]. Journal of Magnetic Resonance, 2021, 328: 107009. DOI: 10.1016/j.jmr.2021.107009.
[13] QIAO Z, LIU P, FANG C, et al. Directional TV algorithm for image reconstruction from sparse-view projections in EPR imaging[J/OL]. Physics in Medicine & Biology, 2024, 69(11): 115051. DOI: 10.1088/1361-6560/ad4a1b.
[14] JIANG M, TAO H W, CHENG K. Sparse view CT reconstruction algorithm based on non-local generalized total variation regularization[J]. CT Theory and Applications, 2025, 34(1): 129-139. DOI: 10.15953/j.ctta.2023.170.
[15] 2022 31 1 1 12 10.15953/j.ctta.2021.053 [16] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[M/OL]//NAVAB N, HORNEGGER J, WELLS W M, et al. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: Vol. 9351. Cham: Springer International Publishing, 2015: 234-241 [2025-01-03]. http://link.springer.com/ 10.1007/978-3-319-24574-4_28. DOI: 10.1007/978-3-319-24574-4_28.
[17] HAN Y S, YOO J, YE J C. Deep residual learning for compressed sensing ct reconstruction via persistent homology analysis[A/OL]. arXiv, 2016[2024-11-30]. http://arxiv.org/abs/1611.06391. DOI: 10.48550/arXiv.1611.06391.
[18] JIN K H, MCCANN M T, FROUSTEY E, et al. Deep Convolutional Neural Network for Inverse Problems in Imaging[J/OL]. IEEE Transactions on Image Processing, 2017, 26(9): 4509-4522. DOI: 10.1109/TIP.2017.2713099.
[19] CHEN H, ZHANG Y, KALRA M K, et al. Low-Dose CT with a residual encoder-decoder convolutional neural network[J/OL]. IEEE Transactions on Medical Imaging, 2017, 36(12): 2524-2535. DOI: 10.1109/TMI.2017.2715284.
[20] GUAN S, KHAN A A, SIKDAR S, et al. Fully Dense UNet for 2-D Sparse Photoacoustic Tomography Artifact Removal[J/OL]. IEEE Journal of Biomedical and Health Informatics, 2020, 24(2): 568-576. DOI: 10.1109/JBHI.2019.2912935.
[21] ZHENG A, GAO H, ZHANG L, et al. A dual-domain deep learning-based reconstruction method for fully 3D sparse data helical CT[J/OL]. Physics in Medicine & Biology, 2020, 65(24): 245030. DOI: 10.1088/1361-6560/ab8fc1.
[22] KANDARPA V S S, PERELLI A, BOUSSE A, et al. LRR-CED: low-resolution reconstruction-aware convolutional encoder–decoder network for direct sparse-view CT image reconstruction[J/OL]. Physics in Medicine & Biology, 2022, 67(15): 155007. DOI: 10.1088/1361-6560/ac7bce.
[23] YU J, ZHANG H, ZHANG P, et al. Unsupervised learning-based dual-domain method for low-dose CT denoising[J/OL]. Physics in Medicine & Biology, 2023, 68(18): 185010. DOI: 10.1088/1361-6560/acefa2.
[24] ZHU Y Z, LV Q W, GUAN Y, et al. Low-dose CT reconstruction based on deep energy models[J]. CT Theory and Applications, 2022, 31(6): 709-720. DOI: 10.15953/j.ctta.2021.077.
[25] HAN Y. Hierarchical decomposed dual-domain deep learning for sparse-view CT reconstruction[J/OL]. Physics in Medicine & Biology, 2024, 69(8): 085019. DOI: 10.1088/1361-6560/ad31c7.
[26] VASWANI A, SHAZEER N, PARMAR N, et al. Attention Is All You Need[A/OL]. arXiv, 2023[2024-11-30]. http://arxiv.org/abs/1706.03762. DOI: 10.48550/arXiv.1706.03762.
[27] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[A/OL]. arXiv, 2021[2024-11-30]. http://arxiv.org/abs/2010.11929. DOI: 10.48550/arXiv.2010.11929.
[28] QIAO Y Y, QIAO Z W. Low-dose CT image reconstruction method based on CNN and transformer coupling network[J]. CT Theory and Applications, 2022, 31(6): 697-707. DOI: 10.15953/j.ctta.2022.114.
[29] LIU P, FANG C, QIAO Z. A dense and U-shaped transformer with dual-domain multi-loss function for sparse-view CT reconstruction[J/OL]. Journal of X-Ray Science and Technology, 2024, 32(2): 207-228. DOI: 10.3233/XST-230184.
[30] YAN H, FANG C, LIU P, et al. CGP-Uformer: A low-dose CT image denoising Uformer based on channel graph perception[J/OL]. Journal of X-Ray Science and Technology, 2023, 31(6): 1189-1205. DOI: 10.3233/XST-230158.
[31] FAN X L, WEN Y Q, QIAO Z W. Sparse reconstruction of computed tomography images with transformer enhanced U-net[J]. CT Theory and Applications, 2024, 33(1): 1-12. DOI: 10.15953/j.ctta.2023.183.
[32] LI Y, SUN X, WANG S, et al. MDST: multi-domain sparse-view CT reconstruction based on convolution and swin transformer[J/OL]. Physics in Medicine & Biology, 2023, 68(9): 095019. DOI: 10.1088/1361-6560/acc2ab.
[33] MCKERAHAN T. Linear Attention Mechanism: An efficient attention for semantic segmentation[J].
[34] WANG S, LI B Z, KHABSA M, et al. Linformer: Self-attention with linear complexity[A/OL]. arXiv, 2020 [2024-11-30]. http://arxiv.org/abs/2006.04768. DOI: 10.48550/arXiv.2006.04768.
[35] CHOROMANSKI K, LIKHOSHERSTOV V, DOHAN D, et al. Rethinking Attention with Performers[A/OL]. arXiv, 2022 [2024-11-30]. http://arxiv.org/abs/2009.14794. DOI: 10.48550/arXiv.2009.14794.
[36] SHEN Z, ZHANG M, ZHAO H, et al. Efficient attention: attention with linear complexities[C/OL]//2021 IEEE Winter Conference on Applications of Computer Vision (WACV). Waikoloa, HI, USA: IEEE, 2021: 3530-3538[2025-01-03]. https://ieeexplore.ieee.org/document/9423033/. DOI: 10.1109/WACV48630.2021.00357.
[37] KATHAROPOULOS A, VYAS A, PAPPAS N, et al. Transformers are RNNs: Fast autoregressive transformers with linear attention[A/OL]. arXiv, 2020[2024-12-09]. https://arxiv.org/abs/2006.16236. DOI: 10.48550/ARXIV.2006.16236.
[38] CHEN H, ZHANG Y, CHEN Y, et al. LEARN: Learned experts’ assessment-based reconstruction network for sparse-data CT[J/OL]. IEEE Transactions on Medical Imaging, 2018, 37(6): 1333-1347. DOI: 10.1109/TMI.2018.2805692.
[39] ZHANG Y, CHEN H, XIA W, et al. LEARN++: Recurrent dual-domain reconstruction network for compressed sensing CT[J/OL]. IEEE Transactions on Radiation and Plasma Medical Sciences, 2023, 7(2): 132-142. DOI: 10.1109/TRPMS.2022.3222213.
[40] CHAE S, YANG E, MOON W J, et al. Deep cascade of convolutional neural networks for quantification of enlarged perivascular spaces in the basal ganglia in magnetic resonance imaging[J/OL]. Diagnostics, 2024, 14(14): 1504. DOI: 10.3390/diagnostics14141504.
[41] AGGARWAL H K, MANI M P, JACOB M. MoDL: Model-based deep learning architecture for inverse problems[J/OL]. IEEE Transactions on Medical Imaging, 2019, 38(2): 394-405. DOI: 10.1109/TMI.2018.2865356.
[42] WANG J, ZENG L, WANG C, et al. ADMM-based deep reconstruction for limited-angle CT[J/OL]. Physics in Medicine & Biology, 2019, 64(11): 115011. DOI: 10.1088/1361-6560/ab1aba.
[43] LIAO H, LIN W A, ZHOU S K, et al. ADN: Artifact Disentanglement Network for Unsupervised Metal Artifact Reduction[J/OL]. IEEE Transactions on Medical Imaging, 2020, 39(3): 634-643. DOI: 10.1109/TMI.2019.2933425.
[44] PUTZKY P, WELLING M. Recurrent inference machines for solving inverse problems[A/OL]. arXiv, 2017[2024-11-30]. http://arxiv.org/abs/1706.04008. DOI: 10.48550/arXiv.1706.04008.
[45] XIANG J, DONG Y, YANG Y. FISTA-Net: Learning a Fast Iterative Shrinkage Thresholding Network for Inverse Problems in Imaging[J/OL]. IEEE Transactions on Medical Imaging, 2021, 40(5): 1329-1339. DOI: 10.1109/TMI.2021.3054167.
[46] WU W, HU D, NIU C, et al. DRONE: Dual-Domain Residual-based Optimization NEtwork for Sparse-View CT Reconstruction[J/OL]. IEEE Transactions on Medical Imaging, 2021, 40(11): 3002-3014. DOI: 10.1109/TMI.2021.3078067.
[47] GENZEL M, GÜHRING I, MACDONALD J, et al. Near-exact recovery for tomographic inverse problems via deep learning[A/OL]. arXiv, 2022[2024-11-30]. http://arxiv.org/abs/2206.07050. DOI: 10.48550/arXiv.2206.07050.
[48] SU T, CUI Z, YANG J, et al. Generalized deep iterative reconstruction for sparse-view CT imaging[J/OL]. Physics in Medicine & Biology, 2022, 67(2): 025005. DOI: 10.1088/1361-6560/ac3eae.
[49] JIA Y, MCMICHAEL N, MOKARZEL P, et al. Superiorization-inspired unrolled SART algorithm with U-Net generated perturbations for sparse-view and limited-angle CT reconstruction[J/OL]. Physics in Medicine & Biology, 2022, 67(24): 245004. DOI: 10.1088/1361-6560/aca513.
[50] SUN C, LIU Y, YANG H. An efficient deep unrolling network for sparse-view CT reconstruction via alternating optimization of dense-view sinograms and images[J/OL]. Physics in Medicine & Biology, 2024[2024-12-22]. https://iopscience.iop.org/article/ 10.1088/1361-6560/ad9dac. DOI: 10.1088/1361-6560/ad9dac.
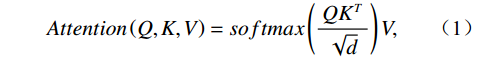
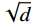
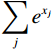
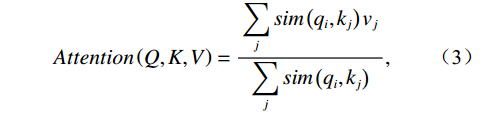
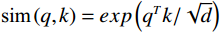
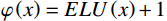
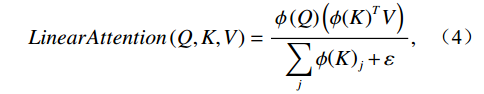
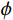
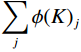

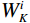
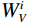
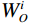
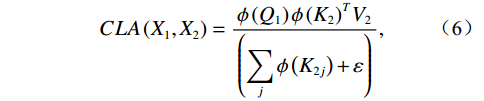
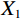
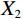
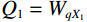
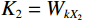
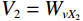
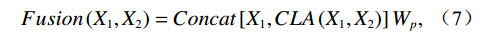
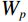
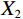
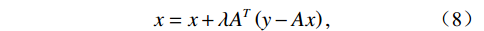
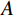
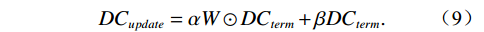
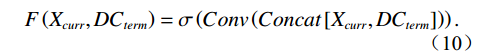
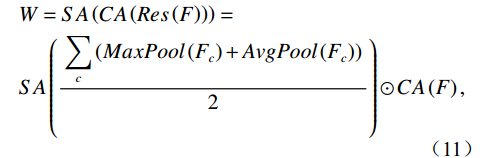

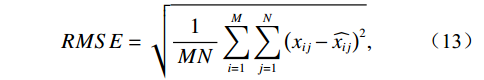
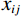
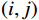
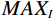
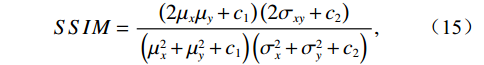
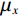
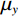
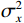
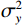
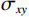
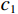
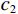


计量
- 文章访问数: 144
- HTML全文浏览量: 13
- PDF下载量: 14


